弊社で提供しているオーダーメイドPC製作サービス TEGSYSでは、お客さまのご要望に合わせ、個別の用途や使用予定のソフトウェアに合わせて、最適なスペックのPCをご提案しております。
理工学・医学・生物学・心理学など様々な分野のお客様よりご指定いただく機会の多いソフトウェアのひとつに、DeepLabCut (動物の行動分析のための動画学習ツール)があります。以前の記事では、複数のGPUで動作を比較しました。
前回学習に用いたサンプルの動画、用意したGPUの範囲では、GPUによって処理時間に差が見られませんでした。
今回は、改めてGPUごとの計算時間の差を検証すると同時に、状況に応じた最適なGPUスペックを推定するため、学習時間を計測しました。
DeepLabCut
動物の行動を分析するためのオープンソースのディープラーニングツール。動画から動物の特定の身体部位を識別しマーカーレスでの追跡が可能で、精度の高い動きの分析を提供する。
検証方法
サイズの異なる3つの動画を用意
学習には扇風機の動画を用いました。
前回の検証では640 x 480 のサイズの動画を使用しましたが、今回は以下の3つのサイズに対して比較検証を行いました。
・HD (1280×720)
・FullHD (1920×1080)
・4K(4096×2160)
扇風機に色付きのシールを張り付け、[1] 赤点、[2]青点、[3]緑点、[4]黄点、[5] ファンの中央の5か所に前回同様ラベルを付けます。
動画は1000fps で撮影しましたが、学習用のラベル付けを行うフレーム数は19フレームと、前回の記事と同フレーム数となり、動画素材のフレームレートは学習に必要な計算処理量には影響しません。
比較するGPUの仕様
本記事で使用したGPUのスペックは下記のとおりです。
| GPU architecture | NVIDIA GeForce RTX 4090 | NVIDIA RTX A6000 | NVIDIA RTX 6000 Ada |
|---|---|---|---|
| CUDA core | 16384コア | 10752コア | 18176コア |
| Tensor core | 512コア | 336コア | 568コア |
| RT core | 128コア | 84コア | 142コア |
| memory size | 24 GB GDDR6X | 48 GB GDDR6 | 48 GB GDDR6 |
| memory bandwidth | Up to 1008GB/s | Up to 768GB/s | Up to 960GB/s |
| Maximum power consumption | 450W | 300W | 300W |
コンピュータ仕様
GPU以外のハードウェア仕様は変更せずパフォーマンスを測定しました。
CPU等のスペックは下記のとおりです。
右手の動画を対象にして、外れ値と推定されるフレームが複数枚抜き出されます。今回の検証では19枚が抜き出されました。
それぞれのフレームを手動で確認し、位置が誤っているフレームがあれば、正しい位置に直します。
| Chipset | Intel W790 |
|---|---|
| CPU | Intel Xeon w7-2465X (3.10GHz 16コア 32スレッド) |
| RAM | 合計64GB (DDR5-4800 ECC Registered 16GB x4) |
| Storage | 1.92TB SSD S-ATA |
学習処理と実行結果
学習処理の実行条件・パラメータ
学習処理の実行条件は下記の通りです。
Network: resnet_50
Augumentation Method: imgaug
Maximum Iterations: 20,000実行結果
4K の動画はエラーにより学習処理を行うことができなかったため、結果からは除外しました。
※詳細はこちらの補足情報をご覧ください
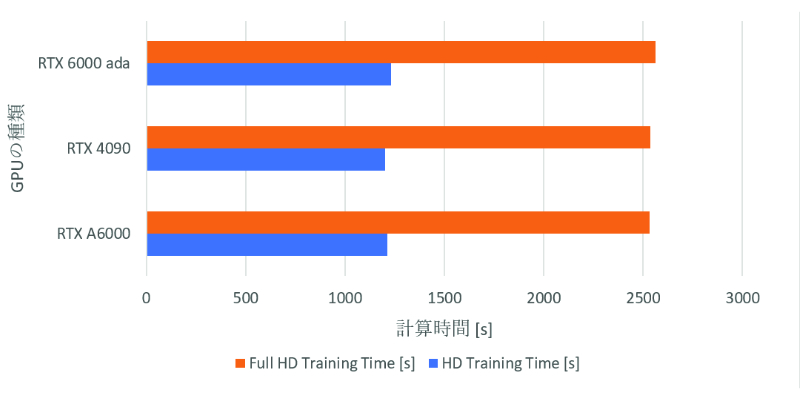
HD、FullHDでは学習処理を行うことができました。各GPUでの計算時間、およびGPU Load の平均値は下記のグラフの通りです。
いずれのGPUでも、HDよりもFullHDの方が計算時間が長いことから、画素数に比例して計算時間が長くなることが確認できました。
その一方で、前回のSD画質の時と同様、3種類のGPU間において、劇的な計算時間の差は見られませんでした。
また、GPU Load からもGPUリソースを活用しきれていない状態が確認できます。
GPU自体の金額的なコストを見た場合、RTX 4090と 比較してRTX A6000 はおおよそ倍、6000 Ada は3倍以上のコスト差があります。
学習の実行条件や設定により変動する可能性はございますが、今回行いました DeepLabCutの学習においては、GPUについては最上位のものを用いる効果は無く、実際の最適スペックの下限値は実測が必要となりますが、RTX 4090 よりも低スペックなGPUの中に最適なコストパフォーマンスが得られるスペックが存在する可能性があります。